
1. 下载源码
https://github.com/neuralchen/SimSwap
2. 下载预模型及依赖文件
下面的下载链接都是官方文档里的链接,如果想省事直接去百度网盘,
下载链接:https://pan.baidu.com/s/12pmRPgW2TRshKBW50_7AzA?pwd=32b0
提取码:32b0
2.1. antelope.zip
insightface人脸识别和对齐模型,下载地址:https://github.com/deepinsight/insightface;下载antelope.zip解压到 ./insightface_func/models目录。
2.2. 79999.iter.pth
face-parsing.PyTorch人脸检测模型,下载地址:https://drive.google.com/file/d/154JgKpzCPW82qINcVieuPH3fZ2e0P812/view;下载后放到 ./parsing_model/checkpoint目录下。
2.3. 预训练模型
arcface_checkpoint.tar:官方预训练模型,下载后复制到 ./arcface_model目录下
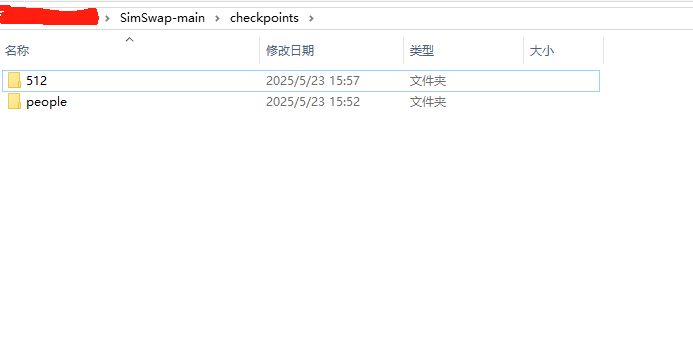
checkpoints.zip:官方预训练模型,下载后解压到根目录
下载地址:
谷歌网盘:https://drive.google.com/drive/folders/1jV6_0FIMPC53FZ2HzZNJZGMe55bbu17R?usp=sharing
百度网盘:https://pan.baidu.com/s/1wFV11RVZMHqd-ky4YpLdcA
密码:jd2v
2.4. 512.zip(可选)
高清模型,下载地址:https://github.com/neuralchen/SimSwap/releases/download/512_beta/512.zip,下载后解压到上面已经解压的文件夹checkpoints中,目录截图见上2.3中的图。
3. 初始化虚拟环境
我的环境为:PyTorch 2.0.0、Python 3.8(ubuntu20.04)、CUDA 11.8,安装官方的步骤,依赖始终有问题,下面是我可以正常运行的依赖:
conda create -n simswap python=3.9
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install numpy==1.24.4
pip install insightface==0.2.1 onnxruntime moviepy
pip install moviepy==1.0.3
4. 测试验证
运行官方的测试脚本:
# 替换图片可信度最高人脸
python test_wholeimage_swapmulti.py --crop_size 224 --use_mask --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path ./demo_file/Iron_man.jpg --pic_b_path ./demo_file/multi_people.jpg --output_path ./output/
# 替换视频人脸,使用512
python test_wholeimage_swap_multispecific.py --crop_size 512 --use_mask --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_b_path ./demo_file/multi_people.jpg --output_path ./output/ --multisepcific_dir ./demo_file/multispecific 5. web服务代码示例
需要安装依赖:
pip install flask==3.1.0
pip install psutil
下面代码中提供了图片换脸和视频换脸两个接口,参数使用base64传输或文件流,返回参数为文件base64编码。
from flask import Flask, request, jsonify
import base64
import cv2
import numpy as np
import os
from test_wholeimage_swapsingle import TestOptions, create_model, Face_detect_crop, watermark_image, SpecificNorm, reverse2wholeimage
import torch
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
from parsing_model.model import BiSeNet
import io
import threading
import traceback
from werkzeug.formparser import RequestEntityTooLarge
from util.videoswap import video_swap
import tempfile
import shutil
import torch.cuda
import psutil
import math
import gc
import atexit
import signal
import time
import random
app = Flask(__name__)
# 设置最大请求大小为 64MB
app.config['MAX_CONTENT_LENGTH'] = 640 * 1024 * 1024 # 640MB
# 设置最大表单字段大小
app.config['MAX_FORM_MEMORY_SIZE'] = 640 * 1024 * 1024 # 640MB
# 设置请求解析器的限制
app.config['MAX_CONTENT_LENGTH'] = None # 禁用全局限制
app.config['WTF_CSRF_ENABLED'] = False # 如果使用了 Flask-WTF,禁用 CSRF
# 在所有 import 之后,Flask app 创建之前添加这些设置
def cleanup_cuda():
"""完全清理 CUDA 资源"""
if torch.cuda.is_available():
# 确保所有 CUDA 张量被释放
torch.cuda.empty_cache()
# 重置 CUDA 设备
torch.cuda.reset_peak_memory_stats()
torch.cuda.reset_accumulated_memory_stats()
# 强制同步所有 CUDA 流
torch.cuda.synchronize()
gc.collect()
# 注册清理函数到进程退出时执行
atexit.register(cleanup_cuda)
# 注册信号处理器
def signal_handler(signum, frame):
cleanup_cuda()
exit(0)
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
class ModelManager:
_instance = None
_lock = threading.Lock()
def __init__(self):
self.opt = None
self.model = None
self.spNorm = None
self.face_app = None
self.parsing_net = None
self._cuda_initialized = False
@classmethod
def get_instance(cls):
if not cls._instance:
with cls._lock:
if not cls._instance:
cls._instance = ModelManager()
return cls._instance
def _init_cuda(self):
"""初始化 CUDA 设置"""
if not self._cuda_initialized and torch.cuda.is_available():
# 设置 CUDA 不要预分配内存
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 禁用 CUDA 缓存分配器
os.environ['PYTORCH_NO_CUDA_MEMORY_CACHING'] = '1'
self._cuda_initialized = True
def get_optimal_cuda_settings(self):
"""根据显卡情况自动设置最优的 CUDA 内存配置"""
try:
# 获取 GPU 总显存(以字节为单位)
gpu_memory = torch.cuda.get_device_properties(0).total_memory
# 转换为 GB
gpu_memory_gb = gpu_memory / (1024**3)
# 获取系统内存信息
system_memory = psutil.virtual_memory()
system_memory_gb = system_memory.total / (1024**3)
# 设置 CUDA 内存分配器的配置
# 对于显存较小的 GPU(<8GB),使用更保守的设置
if gpu_memory_gb < 8:
max_split_size = min(512, math.floor(gpu_memory_gb * 1024 * 0.2)) # 使用 20% 的显存作为分割大小
allocation_conf = f"max_split_size_mb:{max_split_size},garbage_collection_threshold:0.6"
# 对于中等显存的 GPU(8-16GB)
elif gpu_memory_gb < 16:
max_split_size = min(1024, math.floor(gpu_memory_gb * 1024 * 0.3)) # 使用 30% 的显存
allocation_conf = f"max_split_size_mb:{max_split_size},garbage_collection_threshold:0.7"
# 对于大显存 GPU(>=16GB)
else:
max_split_size = min(2048, math.floor(gpu_memory_gb * 1024 * 0.4)) # 使用 40% 的显存
allocation_conf = f"max_split_size_mb:{max_split_size},garbage_collection_threshold:0.8"
# 设置环境变量
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = allocation_conf
# 设置 PyTorch 的内存分配器
torch.cuda.set_per_process_memory_fraction(0.8) # 限制使用最多 80% 的可用显存
# 启用内存缓存
torch.cuda.empty_cache()
print(f"已优化 CUDA 内存设置:GPU显存 {gpu_memory_gb:.1f}GB, "
f"系统内存 {system_memory_gb:.1f}GB, "
f"最大分割大小 {max_split_size}MB")
return True
except Exception as e:
print(f"设置 CUDA 优化参数时出错: {str(e)}")
return False
def load_models(self):
if self.model is None:
print("正在加载模型...")
self._init_cuda()
cleanup_cuda() # 确保开始时没有残留的显存占用
try:
# 检查必要的模型文件
required_files = {
'SimSwap模型': './checkpoints/people/550000_net_G.pth',
'Arcface模型': 'arcface_model/arcface_checkpoint.tar',
'Parsing模型': './parsing_model/checkpoint/79999_iter.pth'
}
missing_files = []
for name, path in required_files.items():
if not os.path.exists(path):
missing_files.append(f"{name}: {path}")
if missing_files:
error_msg = "缺少必要的模型文件:\n" + "\n".join(missing_files)
error_msg += "\n\n请确保已下载所有必要的预训练模型文件,并放置在正确的目录中。"
error_msg += "\n\n您可以从以下地址下载模型文件:"
error_msg += "\n1. SimSwap模型(550000_net_G.pth): https://github.com/neuralchen/SimSwap"
error_msg += "\n2. Arcface模型(arcface_checkpoint.tar): https://github.com/neuralchen/SimSwap/tree/main/arcface_model"
error_msg += "\n3. Parsing模型(79999_iter.pth): https://github.com/neuralchen/SimSwap/tree/main/parsing_model/checkpoint"
raise FileNotFoundError(error_msg)
# 分批加载模型
print("加载 SimSwap 模型...")
self.opt = TestOptions().parse()
self.opt.no_simswaplogo = True
self.opt.isTrain = False
self.opt.use_mask = True
self.opt.name = 'people'
self.opt.Arc_path = 'arcface_model/arcface_checkpoint.tar'
self.opt.crop_size = 512
self.opt.which_epoch = 550000
# 确保模型加载到 CUDA 时立即进行内存优化
with torch.cuda.device(0):
self.model = create_model(self.opt)
self.model.cuda() # 确保模型在GPU
self.model.eval()
torch.cuda.empty_cache()
print("加载人脸检测模型...")
self.face_app = Face_detect_crop(name='antelope', root='./insightface_func/models')
self.face_app.prepare(ctx_id=0, det_thresh=0.6, det_size=(640,640), mode='ffhq')
torch.cuda.empty_cache()
print("加载 Parsing 模型...")
n_classes = 19
self.parsing_net = BiSeNet(n_classes=n_classes)
self.parsing_net.cuda()
save_pth = os.path.join('./parsing_model/checkpoint', '79999_iter.pth')
self.parsing_net.load_state_dict(torch.load(save_pth))
self.parsing_net.eval()
torch.cuda.empty_cache()
self.spNorm = SpecificNorm()
print("所有模型加载完成")
except Exception as e:
self.unload_models() # 确保错误时完全释放资源
raise Exception(f"模型加载失败: {str(e)}")
def unload_models(self):
"""完全卸载所有模型并释放 CUDA 资源"""
if self.model is not None:
print("释放模型...")
try:
# 将所有模型移到 CPU 并删除
if hasattr(self, 'model'):
self.model.cpu()
del self.model
if hasattr(self, 'parsing_net'):
self.parsing_net.cpu()
del self.parsing_net
if hasattr(self, 'face_app'):
del self.face_app
if hasattr(self, 'spNorm'):
del self.spNorm
self.model = None
self.parsing_net = None
self.face_app = None
self.spNorm = None
self.opt = None
# 强制进行垃圾回收
gc.collect()
cleanup_cuda()
print("模型已完全释放")
except Exception as e:
print(f"释放模型时出错: {str(e)}")
# 即使出错也要尝试清理
cleanup_cuda()
# 图片转换函数
transformer_Arcface = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
def _totensor(array):
tensor = torch.from_numpy(array)
img = tensor.transpose(0, 1).transpose(0, 2).contiguous()
return img.float().div(255)
def base64_to_image(base64_str):
img_data = base64.b64decode(base64_str)
nparr = np.frombuffer(img_data, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
return img
def image_to_base64(img):
_, buffer = cv2.imencode('.jpg', img)
img_base64 = base64.b64encode(buffer).decode('utf-8')
return img_base64
@app.route('/swap_face', methods=['POST'])
def swap_face():
request_id = str(threading.get_ident())
start_time = time.time()
print(f"[{request_id}] 收到请求 - 开始时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
try:
# 获取 ModelManager 实例
model_manager = ModelManager.get_instance()
print(f"[{request_id}] 获取请求数据...")
# 获取原始数据并解析
content_type = request.headers.get('Content-Type', '')
if 'application/x-www-form-urlencoded' in content_type:
# 手动解析 URL 编码的表单数据
from urllib.parse import parse_qs
raw_data = request.get_data().decode('utf-8')
form_data = parse_qs(raw_data)
img_a_base64 = form_data.get('source', [None])[0]
img_b_base64 = form_data.get('target', [None])[0]
elif 'multipart/form-data' in content_type:
# 对于 multipart/form-data,仍然使用 request.form
img_a_base64 = request.form.get('source')
img_b_base64 = request.form.get('target')
else:
# 尝试作为 JSON 处理
try:
json_data = request.get_json()
img_a_base64 = json_data.get('source')
img_b_base64 = json_data.get('target')
except:
raise ValueError("不支持的 Content-Type,请使用 application/x-www-form-urlencoded, multipart/form-data 或 application/json")
if not img_a_base64 or not img_b_base64:
raise ValueError("缺少必要的字段:'source' 或 'target'")
print(f"[{request_id}] 解码 Base64 图片...")
img_a_whole = base64_to_image(img_a_base64)
img_b_whole = base64_to_image(img_b_base64)
if img_a_whole is None:
raise ValueError("解码源图片失败 (source)")
if img_b_whole is None:
raise ValueError("解码目标图片失败 (target)")
print(f"[{request_id}] 源图片尺寸: {img_a_whole.shape}, 目标图片尺寸: {img_b_whole.shape}")
with torch.no_grad():
print(f"[{request_id}] 处理源图片 (人脸检测和特征提取)...")
img_a_align_crop, _ = model_manager.face_app.get(img_a_whole, model_manager.opt.crop_size)
if not img_a_align_crop:
raise ValueError("在源图片中未检测到人脸")
img_a_align_crop_pil = Image.fromarray(cv2.cvtColor(img_a_align_crop[0], cv2.COLOR_BGR2RGB))
img_a = transformer_Arcface(img_a_align_crop_pil)
img_id = img_a.view(-1, img_a.shape[0], img_a.shape[1], img_a.shape[2]).cuda()
# 确保模型也在cuda
assert next(model_manager.model.parameters()).is_cuda
print(f"[{request_id}] 计算源图片特征向量...")
img_id_downsample = F.interpolate(img_id, size=(112,112))
latend_id = model_manager.model.netArc(img_id_downsample)
latend_id = F.normalize(latend_id, p=2, dim=1)
print(f"[{request_id}] 源图片特征向量计算完成")
print(f"[{request_id}] 处理目标图片 (人脸检测)...")
img_b_align_crop_list, b_mat_list = model_manager.face_app.get(img_b_whole, model_manager.opt.crop_size)
if not img_b_align_crop_list:
print(f"[{request_id}] 警告: 在目标图片中未检测到人脸,将尝试直接处理整张图片 (可能效果不佳)")
# 如果未检测到人脸,可以考虑是否返回错误或尝试其他处理
# 这里我们继续,但 reverse2wholeimage 可能需要处理空列表的情况
# 或者,你可以选择在这里抛出错误:
# raise ValueError("在目标图片中未检测到人脸")
swap_result_list = []
b_align_crop_tenor_list = []
print(f"[{request_id}] 对目标图片中的每张人脸进行换脸...")
for i, b_align_crop in enumerate(img_b_align_crop_list):
print(f"[{request_id}] 处理目标人脸 {i+1}/{len(img_b_align_crop_list)}...")
b_align_crop_tenor = _totensor(cv2.cvtColor(b_align_crop,cv2.COLOR_BGR2RGB))[None,...].cuda()
swap_result = model_manager.model(None, b_align_crop_tenor, latend_id, None, True)[0]
swap_result_list.append(swap_result)
b_align_crop_tenor_list.append(b_align_crop_tenor)
print(f"[{request_id}] 目标人脸处理完成")
temp_output = f'temp_output_{request_id}.jpg'
print(f"[{request_id}] 将结果合成回原图: {temp_output}...")
reverse2wholeimage(
b_align_crop_tenor_list,
swap_result_list,
b_mat_list,
model_manager.opt.crop_size,
img_b_whole,
None,
temp_output,
True,
pasring_model=model_manager.parsing_net,
use_mask=True,
norm=model_manager.spNorm
)
print(f"[{request_id}] 合成完成")
print(f"[{request_id}] 读取并编码结果图片...")
if not os.path.exists(temp_output):
raise FileNotFoundError(f"合成后的临时文件未找到: {temp_output}")
result_img = cv2.imread(temp_output)
if result_img is None:
raise ValueError(f"读取合成后的临时文件失败: {temp_output}")
result_base64 = image_to_base64(result_img)
print(f"[{request_id}] 编码完成")
print(f"[{request_id}] 删除临时文件: {temp_output}...")
if os.path.exists(temp_output):
os.remove(temp_output)
print(f"[{request_id}] 临时文件已删除")
end_time = time.time()
duration = end_time - start_time
print(f"[{request_id}] 请求处理完成 - 结束时间: {time.strftime('%Y-%m-%d %H:%M:%S')}, 总耗时: {duration:.2f}秒")
return jsonify({
'status': 'success',
'data': result_base64
})
except Exception as e:
end_time = time.time()
duration = end_time - start_time
print(f"[{request_id}] 处理请求时发生错误 - 结束时间: {time.strftime('%Y-%m-%d %H:%M:%S')}, 总耗时: {duration:.2f}秒")
traceback.print_exc()
return jsonify({
'status': 'error',
'message': f"处理请求时发生错误: {str(e)}"
}), 500
@app.route('/swap_face_video', methods=['POST'])
def swap_face_video():
request_id = str(threading.get_ident())
start_time = time.time()
print(f"[{request_id}] 收到视频换脸请求 - 开始时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
# 获取 ModelManager 实例
model_manager = ModelManager.get_instance()
input_video_path = None
output_video_path = None
temp_results_dir = None
try:
# 移除模型加载相关代码
print(f"[{request_id}] 获取表单数据 (target, captured_video)...")
source_image_base64 = request.form.get('target')
target_video_base64 = request.form.get('captured_video')
if not source_image_base64 or not target_video_base64:
if not request.form:
raise ValueError("未接收到有效的表单数据。请确保使用 multipart/form-data 或 application/x-www-form-urlencoded 发送请求,并包含 'target' 和 'captured_video' 字段。")
else:
missing = []
if not source_image_base64: missing.append("'target'")
if not target_video_base64: missing.append("'captured_video'")
raise ValueError(f"表单数据中缺少必要的字段: {', '.join(missing)}")
# --- 处理源图片 (现在来自 'target' 字段) ---
print(f"[{request_id}] 解码源图片 Base64 (来自 'target' 字段)...")
img_a_whole = base64_to_image(source_image_base64)
if img_a_whole is None:
raise ValueError("解码源图片失败 (target)")
print(f"[{request_id}] 源图片尺寸: {img_a_whole.shape}")
with torch.no_grad():
print(f"[{request_id}] 处理源图片 (人脸检测和特征提取)...")
img_a_align_crop, _ = model_manager.face_app.get(img_a_whole, model_manager.opt.crop_size)
if not img_a_align_crop:
raise ValueError("在源图片中未检测到人脸")
img_a_align_crop_pil = Image.fromarray(cv2.cvtColor(img_a_align_crop[0], cv2.COLOR_BGR2RGB))
img_a = transformer_Arcface(img_a_align_crop_pil)
img_id = img_a.view(-1, img_a.shape[0], img_a.shape[1], img_a.shape[2]).cuda()
# 确保模型也在cuda
assert next(model_manager.model.parameters()).is_cuda
print(f"[{request_id}] 计算源图片特征向量...")
img_id_downsample = F.interpolate(img_id, size=(112,112))
latend_id = model_manager.model.netArc(img_id_downsample)
latend_id = F.normalize(latend_id, p=2, dim=1)
print(f"[{request_id}] 源图片特征向量计算完成")
# --- 处理目标视频 (现在来自 'captured_video' 字段) ---
print(f"[{request_id}] 解码目标视频 Base64 (来自 'captured_video' 字段) 并保存到临时文件...")
try:
video_data = base64.b64decode(target_video_base64)
except Exception as decode_err:
raise ValueError(f"解码目标视频 Base64 失败: {decode_err}")
# 创建临时输入视频文件
with tempfile.NamedTemporaryFile(suffix=".mp4", delete=False) as temp_in_video:
temp_in_video.write(video_data)
input_video_path = temp_in_video.name
print(f"[{request_id}] 临时输入视频已保存到: {input_video_path}")
# 定义临时输出路径和工作目录
output_video_path = f'temp_output_video_{request_id}.mp4'
temp_results_dir = tempfile.mkdtemp(prefix=f"simswap_temp_{request_id}_")
print(f"[{request_id}] 临时输出视频路径: {output_video_path}")
print(f"[{request_id}] 临时工作目录: {temp_results_dir}")
# --- 执行视频换脸 ---
print(f"[{request_id}] 开始执行视频换脸...")
video_swap(input_video_path, # 位置参数 1: video_path
latend_id, # 位置参数 2: latent_id
model_manager.model,# 位置参数 3: model
model_manager.face_app, # 位置参数 4: app
output_video_path, # 位置参数 5: output_path
temp_results_dir=temp_results_dir, # 关键字参数
no_simswaplogo=model_manager.opt.no_simswaplogo, # 关键字参数
use_mask=model_manager.opt.use_mask, # 关键字参数
crop_size=model_manager.opt.crop_size) # 关键字参数
print(f"[{request_id}] 视频换脸执行完成")
# --- 处理输出视频 ---
print(f"[{request_id}] 读取并编码输出视频...")
if not os.path.exists(output_video_path):
raise FileNotFoundError(f"生成的输出视频文件未找到: {output_video_path}")
with open(output_video_path, "rb") as video_file:
video_binary_data = video_file.read()
result_video_base64 = base64.b64encode(video_binary_data).decode('utf-8')
print(f"[{request_id}] 输出视频编码完成")
end_time = time.time() # 添加结束时间记录
duration = end_time - start_time # 计算耗时
print(f"[{request_id}] 请求处理完成 - 结束时间: {time.strftime('%Y-%m-%d %H:%M:%S')}, 总耗时: {duration:.2f}秒")
return jsonify({
'status': 'success',
'data': result_video_base64
})
except Exception as e:
end_time = time.time()
duration = end_time - start_time
print(f"[{request_id}] 处理视频换脸请求时发生错误 - 结束时间: {time.strftime('%Y-%m-%d %H:%M:%S')}, 总耗时: {duration:.2f}秒")
traceback.print_exc()
return jsonify({
'status': 'error',
'message': f"处理视频换脸请求时发生错误: {str(e)}"
}), 500
finally:
# --- 清理临时文件和目录 ---
print(f"[{request_id}] 清理临时文件和目录...")
if input_video_path and os.path.exists(input_video_path):
try:
os.remove(input_video_path)
print(f"[{request_id}] 已删除临时输入视频: {input_video_path}")
except Exception as rm_err:
print(f"[{request_id}] 删除临时输入视频失败 {input_video_path}: {rm_err}")
if output_video_path and os.path.exists(output_video_path):
try:
os.remove(output_video_path)
print(f"[{request_id}] 已删除临时输出视频: {output_video_path}")
except Exception as rm_err:
print(f"[{request_id}] 删除临时输出视频失败 {output_video_path}: {rm_err}")
if temp_results_dir and os.path.exists(temp_results_dir):
try:
shutil.rmtree(temp_results_dir)
print(f"[{request_id}] 已删除临时工作目录: {temp_results_dir}")
except Exception as rmtree_err:
print(f"[{request_id}] 删除临时工作目录失败 {temp_results_dir}: {rmtree_err}")
# 在应用启动时加载模型
def init_app():
"""初始化应用,加载模型"""
print("正在初始化应用...")
model_manager = ModelManager.get_instance()
model_manager.load_models()
print("应用初始化完成")
# 在应用退出时卸载模型
@atexit.register
def cleanup_on_exit():
"""在应用退出时清理所有资源"""
print("正在清理资源...")
model_manager = ModelManager.get_instance()
model_manager.unload_models()
cleanup_cuda()
if __name__ == '__main__':
init_app() # 在启动服务前加载模型
app.run(host='0.0.0.0', port=5501) 6. 其他问题
可能会出现:GLIBCXX相关问题需要升级版本
#查看当前
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
# 安装高版本 libstdc++
conda install -c conda-forge libgcc-ng
# 临时生效
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib
#永久生效
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib" >> ~/.bashrc
source ~/.bashrc